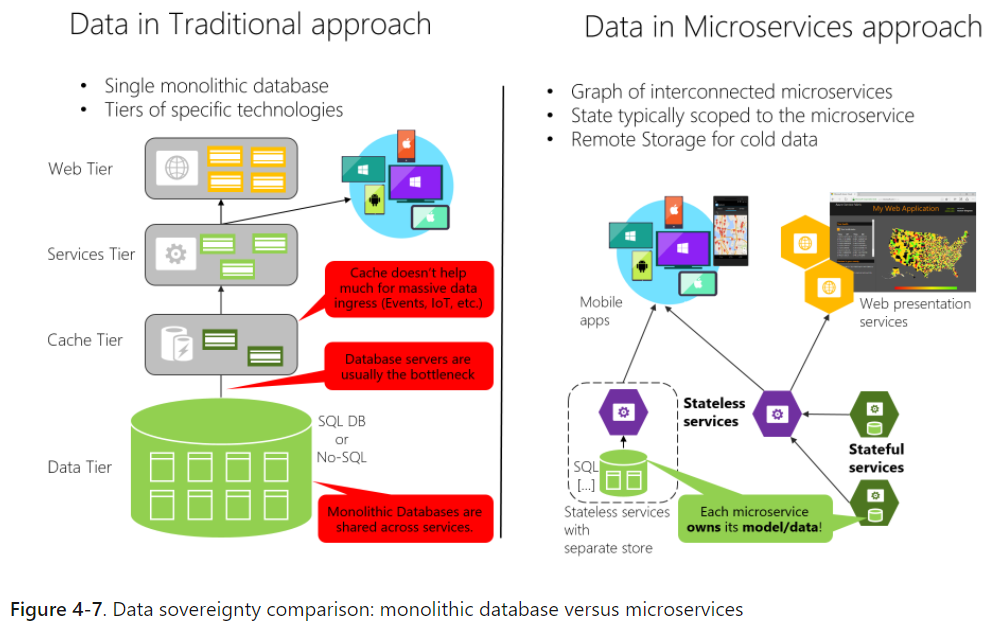
In the traditional approach, there’s a single database shared across all services, typically in a tiered architecture. In the microservices approach, each microservice owns its model/data. Encapsulating the data ensures that the micro services are loosely coupled and can evolve independently of one another. If multiple services were accessing the same data, schema updates would require coordinated updates to all the services. This would break the microservice lifecycle autonomy.
Microservices-based applications often use a mixture of SQL and NoSQL databases. A partitioned, polyglot-persistent architecture for data storage has many benefits. These include loosely coupled services and better performance, scalability, costs, and manageability. However, it can introduce some distributed data management challenges, as explained in “Identifying domain-model boundaries” later in this chapter. The relationship between microservices and the Bounded Context pattern is explained later in the chapter.
Bounded Context and microservice patterns are closely related. A microservice is therefore like a Bounded Context, but it also specifies that it’s a distributed service. It’s important to highlight that defining a service for each Bounding Context is a good place to start. But you don’t have to constrain your design to it. The domain-driven design (DDD) benefits from microservices by getting real boundaries in the form of distributed microservices.
Microservices6