Pavlovian conditioning refers to the ability of previously neutral stimuli to reliably co-occur with primary rewards. In practice, the distinction is often blurry as the two types of conditioning interact. The dominant theoretical perspective for both Pavlovian and instrumental conditioning since the seminal Rescorla and Wagner model, is that learning is based on the discrepancy between actual rewards received and predictions thereof (i.e., reward prediction error) The authors argue that a robust model of Pavlov’s learning should account for the full range of signature findings in the rich literature on this phenomenon.
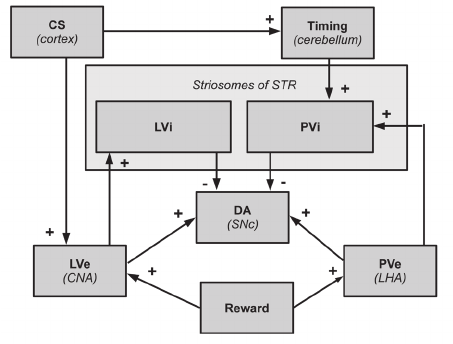
The TD model does not map directly onto the large collection of neural substrates known to be involved in reinforcement learning. Most researchers agree that the critical learning processes are taking place from the midbrain dopamine neurons themselves. In this article, we offer a multicomponent model of Pavlovian learning called PVLV, which provides a more direct mapping onto the underlying neural substrate. PVLV is composed of two subsystems: primary value (PV) and learned value (LV).
The LV system learns about conditioned stimuli that are reliably associated with primary rewards, and it drives phasic dopamine burst firing at the time of CS onset. The PV and LV systems are further subdivided into excitatory and inhibitory subcomponents. This decomposition is similar to the model of Brown et al., but there are several important functional and anatomical differences between the two models. In addition to these core PVLV mechanisms, a number of other brain areas play a critical role in reinforcement learning.
We believe this sort of actively maintained working memory representation is particularly crucial in trace conditioning paradigms in which there is an interval of time between CS-offset and US-onset. As we discuss later, PVLV explicitly accounts for known dissociations between delay and trace conditioning.
Auto206