Part 6: Work
The fun and hard work portion machine learning is getting to apply a bunch of algorithms. Unfortunately, this is just a small part. It is like training for six months for nine minutes (three rounds).

A post about the scikit-learn algorithm and cheat sheet will come later.
One of the common mistakes is to use random set of algorithms without any reasoning. To select the first algorithm to try, you should investigate the problem first.
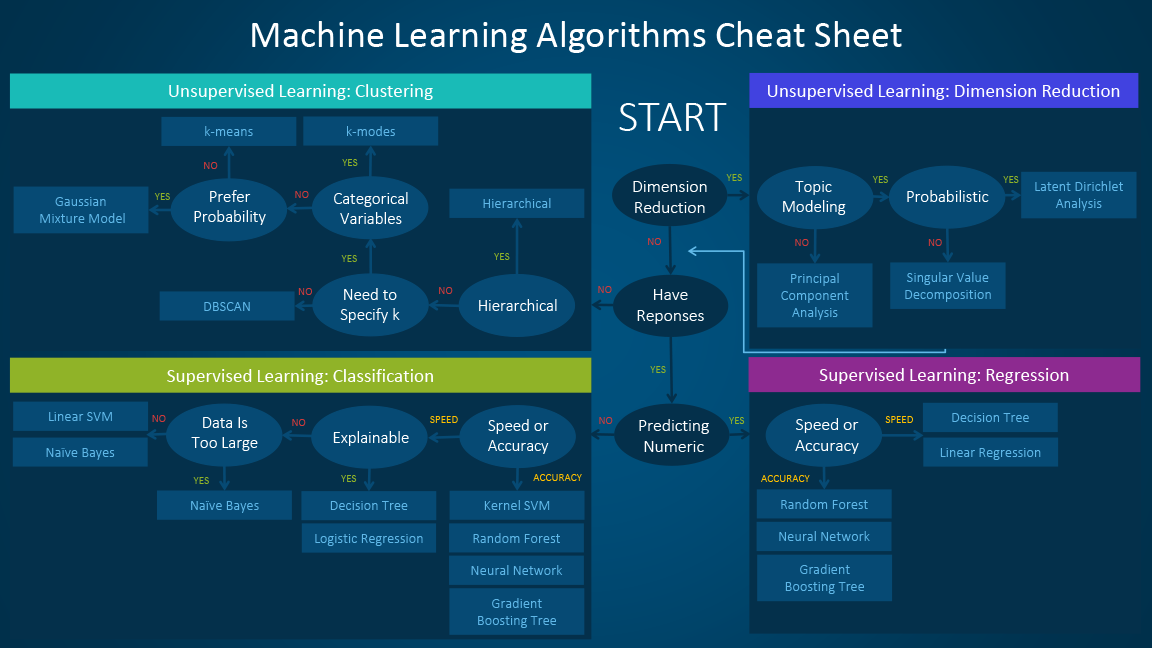
Categorize the problem
- Input
- If it is a labeled data, it’s a supervised learning problem.
- If it’s unlabeled data and the purpose is to find structure, it’s an unsupervised learning problem.
- If the solution is to optimize a function by interacting with an environment, it’s a reinforcement learning problem.
- Output
- If the output of the model is a number, it’s a regression problem.
- If the output of the model is a class, it’s a classification problem.
- If the output of the model is a set of input groups, it’s a clustering problem.
Understand Your Data
Data itself is not the end game because data is the fuel! A good machine learning algorithm can deliver insights to drive better decisions. Understanding your data is the key in choosing the right algorithm for the right problem.
Find the available algorithms
After categorizing the problem and understanding the data, I have to identify the algorithms. Here are some of the elements that I consider.
- The accuracy of the model – not too important
- The interpretability of the model – important
- The complexity of the model – need a simple model for the initial round
- The scalability of the model – model need to scale because I have more data
- How long does it take to build, train, and test the model? – not too important because this is a marathon for me.
- How long does it take to make predictions using the model? – this is important because I need the model to predict so that I can apply a sanity check.
- Does the model meet the business goal? – important
Implement machine learning algorithms.
Set up a machine learning algorithm that compares the performance of each algorithm on a data set – Asian business. Another approach is to use the same algorithm on different subgroups of data sets (Blacks businesses, Hispanic businesses, and White businesses).
Optimize hyper parameters. There are three options for optimizing hyper parameters, grid search, random search, and Bayesian optimization. Model parameters are estimated from data automatically model hyper parameters are parts of the machine learning that must be set manually and tuned.